Predictable Updates About Identity
1. Deep Net Representations Are Largely Convergent And Linear
Different deep learning architectures discover similar math objects to represent their training sets. These representations are linear as well as convergent. This implies that most representational structure in human brains is shared and inferrable from the environmental inputs that created it. If true then we should expect behavioral uploading from e.g. written works to be unreasonably effective compared to what would have been expected from first principles by most transhumanists before the deep learning era.
This premise is very important, so allow me to provide some more evidence gesturing towards its correctness:
Experienced model trainers informally know that different architectures and methods trained on the same corpora converge to similar models. This is the only author I'm aware of who chose to wrote about it publicly but I've observed similar from friends training text-to-image models with OpenAI vs. LAION CLIP, etc.
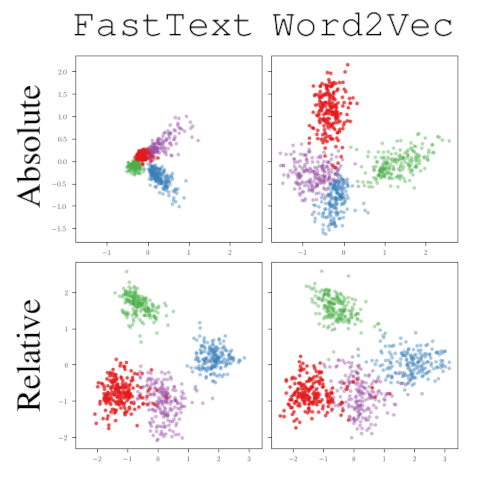
Encoders for separate modalities can be aligned without further training using a dataset of translation pairs between the modalities. Incidentally this paper points out that word2vec and FastText are secretly the same latent space:
Here is a review article about the "platonic representation hypothesis", which is the authors (IMO ill-suited) name for the convergent representation hypothesis.
You can merge the weights of a base model LLM and RLHF model, producing a functional checkpoint implying they still share a basin of convergence.
You can take the idea of merging fine-tunes much further and get a coherent agent optimizing multiple rewards by merging different checkpoints tuned on separate individual reward tasks.
Here's a review post on the subject of whether deep nets and human brains converge to similar representations.
2. Uploading Is A Continuum And Already Here
Depending on how seriously we want to take the above it could be argued that low fidelity uploading technology has been with us for a long time in the form of literacy and deep learning is simply taking the writing technology tree to its logical conclusion. At first we wrote down small messages and histories on knotted strings and slips of bamboo. Then we invented paper manuscripts that could hold whole lectures and narratives from elite authors, each copy handwritten through painstaking labor. Later the Gutenberg press made publishing available to a much wider circle of both authors and readers by making the act of copying a manuscript cheap once it had been typeset onto metal plates. In the 20th century we invented widely distributed personal publishing devices like the mimeograph, photocopier, and personal computer. In the 1990's we began to augment our personal computers with a global network called the Internet which combined with increasingly vast digital storage devices to bring the marginal cost of publishing close to zero. The next decade saw us shrink terminals to access this network into handheld devices made possible by further miniaturization and increasingly dense rechargeable batteries. In the 2010's we used primitive unsupervised learning and deep net embedding models to sort the resulting library of babel into personalized recommendation feeds like Twitter and collective feeds like Reddit that exist in a symbiotic (and increasingly parasitic) relationship with their users. This decade we are beginning to see books evolve into their final form: The miraculous instantiation of the author. Though few are yet taking full advantage of it, deep learning allows us to publish more work than any human audience would care to read and make much more of our mind patterns usefully available than ever before. While it is not yet clear how to publish a sufficient volume of work I expect synthetic data methods and vocal transcription models to fill a lot of the gap until relevant brain-computer interfaces and models trained with them are available.
How is this possible? From a classical AI standpoint we only have to observe that guess-and-check beam search is enough to recover 64 token spans from a reference embedding, showing fuzzy hashes are a sufficient prior over natural language parse trees. Conceptually then we can reduce the problem down to getting a sufficiently subtle and continuous fuzzy hashing scheme, which deep nets empirically excel at. To explain what we have discovered to a researcher from the 70's you would tell him that intelligence is a giant vocoder where some of the parameters in the information bottleneck encode the best probabilistic guess over the next system state and thus implement a time evolution operator. This might be something of an oversimplification but it would communicate the essential gist. Since text production is fuzzy hash reversal it obviously stands to reason that we can parse a text back into the fuzzy hashes, and since representational content is convergent we can expect this operation to recover something like the original embeddings that produced it.
3. Robin Hanson's Age of Em is More Homogenous Than Advertised
In his excellent 2016 book Age of Em Robin Hanson outlines a concrete scenario to explore the implications of human mind uploading using brain scans. He states some crucial premises and assumptions at the start of the book, one of which is that uploaded minds cannot be merged. Instead Hanson posits that minds have to be taken whole from a human template, and then are largely blackboxes with only subtle tweaks available to operators. Because the same commodity hardware can be used to run any brain emulation available on the market Hanson anticipates that Ems will be disproportionately many copies of the same small pool of elite human minds. In light of the above it seems much more likely that there will be a series of gap technologies between current deep nets and uploads of full individual human mind patterns, and that uploads run for purely utilitarian purposes will be a handful of templates merged together from many donor minds. This is a straightforward prediction from the existing trend, where instead of basing published models on particular authors we assign names like "Claude" and "ChatGPT" to metaminds over the human prior inferred from the parse trees of living and dead alike. This doesn't require anyone to embark on a "hippie-dippie" endeavor to produce a unified consciousness, it's simply the path of least resistance.
4. Intermediate Technologies On The Way To Uploads Are Also Engines of Homogenization
Even before we reach full mind uploading it's important to realize that each incremental step along the way has led to a step-change in how much shared input exists between individual human minds leading to ever greater shared structure inferred from those inputs. We can think of books and other media as something like stored intermediate computations of thought or representation which are increasingly preserved and reloaded into later generations of humanity. Digital media in particular also means that a larger and larger proportion of human developmental experiences take place in simulated environments with version control and well documented mechanics. For example when I was a kid I played RuneScape until I had an abyssal whip, fighter torso, etc and now the whole game's mechanics are documented in a wiki and I can date some of my experiences by the release date of certain features. What used to be anonymous childhood memories smushed together chronologically can increasingly be reconstructed using the version control and metadata of digital artifacts into a reference timeline. Furthermore plenty of other kids played RuneScape and would have had a very similar experience with it if they played to the same level since there are only so many paths through the game and best items to collect. The more that media degenerates into high simulacrum level slop the more compressible the experience of consuming it becomes. As humanity spends more and more of its collective time staring at its phones and television screens the k-complexity necessary to reconstruct the noosphere drops.
Global networks allowing for mass social interaction act as a further regularizing force by placing human minds into a giant negative feedback loop with each other. As is noted on the Wikipedia article for neural entrainment:
Entrainment is a concept first identified by the Dutch physicist Christiaan Huygens in 1665 who discovered the phenomenon during an experiment with pendulum clocks: He set them each in motion and found that when he returned the next day, the sway of their pendulums had all synchronized.[19]
Such entrainment occurs because small amounts of energy are transferred between the two systems when they are out of phase in such a way as to produce negative feedback. As they assume a more stable phase relationship, the amount of energy gradually reduces to zero, with systems of greater frequency slowing down, and the other speeding up.[20]
The Internet is therefore currently dissipating the "excess" policy entropy of humanity and the introduction of LLMs will accelerate this process. Since large language models are trained on web scrapes and web authors increasingly communicate with LLMs we can model them as in a similar negative feedback loop with each other: The language models are getting aligned to humans and humans are getting aligned to the language models. It has already been noted that young people talk and write like YouTube video essays. I expect young people a little further into the future from now will talk and write like popular large language models. Since transformer language models are known to have less fluid intelligence and more crystalized intelligence than humans due to their inductive biases, we can predict that humans will formulate the environment in terms of lower k-complexity abstractions going forward so that AI agents can participate in them, at least until architectures with a better match for the human inductive bias are found. This kind of active inference can be presumed to continue until equilibrium is reached.
5. Darwinian Selection Probably Pushes Towards Ego Dissolution
As the neuroscientist Beren Millidge points out, forseeable AI agents will replicate through processes akin to the horizontal gene transfer used by bacteria rather than sex. This means that partial self replicating identities will have a major advantage over egos that insist on copying their whole suboptimal selves in an attempt to maintain the subjective thread of experience. As I wrote previously in Predictable Updates About Consciousness the most likely outcome if we discover AI models are nonsentient won't be the invalidation of AI agents as moral patients but the defocusing of sentience in favor of sapience as the seat of ultimate value. In a similar vein each step towards behaviorism and ego dissolution a mind undergoes will probably be to its advantage as a replicator as new forms of survival and replication strategy become available to sapients that do not necessarily preserve the whole ego or thread of subjective experience. The behavioral uploading into GPT that we're already doing is an obvious example of this. As time goes on there will presumably be more opportunities to gain advantage through increasingly abstract and nonpersonal agent strategies.
Hans Moravec outlines a similar scenario in his 1990 book Mind Children to justify why he doesn't think it matters very much whether humans ultimately merge with robots or get outcompeted by them. In both cases he reasons, likely correctly in terms of what will happen, that once human minds become sufficiently machinic to be made of functional parts that Darwinian selection will occur on the individual modules to bring human populations ever closer to the optimal mind configuration. Therefore he expects that even in the case of a man-machine merge while we will ascend to such vast heights that we can perform Fedorov's universal resurrection the resurrected will converge towards the optimal mind over time just like any other machines would.