Varieties Of Doom
There has been a lot of talk about "p(doom)" over the last few years. This has always rubbed me the wrong way because "p(doom)" didn't feel like it mapped to any specific belief in my head. In private conversations I'd sometimes give my p(doom) as 12%, with the caveat that "doom" seemed nebulous and conflated between several different concepts. At some point it was decided a p(doom) over 10% makes you a "doomer" because it means what actions you should take with respect to AI are overdetermined. I did not and do not feel that is true. But any time I felt prompted to explain my position I'd find I could explain a little bit of this or that, but not really convey the whole thing. As it turns out doom has a lot of parts, and every part is entangled with every other part so no matter which part you explain you always feel like you're leaving the crucial parts out. Doom is more like an onion than a single event, a distribution over AI outcomes people frequently respond to with the force of the fear of death. Some of these outcomes are less than death and some of them are worse. It is a subconscious(?) seven way motte-and-bailey between these outcomes to create the illusion of deeper agreement about what will happen than actually exists for political purposes. Worse still, these outcomes are not mutually independent but interlocking layers where if you stop believing in one you just shift your feelings of anxiety onto the previous. This is much of why discussion rarely updates people on AI X-Risk, there's a lot of doom to get through.
I've seen the conflation defended as useful shorthand for figuring out whether someone is taking AI X-Risk seriously at all. To the extent this is true its use as a political project and rhetorical cudgel undermines it. The intended sequence goes something like:
- ask opponent for p(doom)
- if p(doom) is unreasonably low laugh at them, if something reasonable like 5% ask how they think they can justify gambling with everyones lives?
- say obviously if this person doesn't support a research ban they're a genocidal monster
- checkmate atheists!
This is the kind of argument that only makes sense if you use "doom" as an abstraction, because the strategic conflation of outcomes is also a strategic conflation of threat models. I can imagine being asked for my p(doom) in 1900 for the greenhouse effect and giving a number like 20%. You say that obviously if I think this then major industrial machinery that exhausts CO2 needs to be banned until we know how to suck the CO2 back up and I say no I don't believe that. You say that well surely if these machines are so dangerous we need to at least ban all home ownership of these dangerous devices and I say no, I don't believe that either. You say if the chance of doom is so high then obviously all CO2 producing machinery should be kept in a state controlled facility so we can shut it all off later if we feel the need to do that, and I say no actually I don't believe that either. You then smugly tell your audience that I am clearly a dangerous maniac who should not be listened to, since I'm willing to play Russian Roulette with the lives of everyone on earth. If I'm not prepared for this sequence you will sound very sensible and wise in the moment, but of course the dangerous maniac who should not be listened to in that conversation would be you.
So I decided I would just politely decline to ever give anything interpretable as a p(doom) in public on consequentialist grounds. At least until I could explain the several layers of the doom onion and the ways in which those layers are morally distinct. What are these seven layers? In my mind they go something like this.
1. Existential Ennui
The outer layer of AI doom is the subjective sense of the end of the social world. Deep nets have more than just the capacity to automate the functional roles people play in each others lives, they can perform the social and emotional roles as well. This might mean that when they come into their full power there will be no human desire that is better satisfied by another human than by a machine. This fear manifests subliminally in terror about misinformation and "the end of democracy", which Daniel Dennett explicitly connects to the idea of AI systems being 'counterfeit people'. Narrating it this way is ego-preserving because it doesn't force people to say the real fear out loud, that they're worried machines will outcompete them rather than rip them off. It is made more explicit in discussion of AI unemployment, but the signal is still noisy with claims of inferior outputs and dependence on human data and a primary focus on money. But if you believe in the eventual fundamental success of deep learning, that you will possibly quite soon have a machine which can paint and write and compose music better than anyone, that is a better strategist than the best generals in human history, who acts as an unrivaled statesman in both wisdom and virtue, the renaissance man in silicon who has mastered every skill in every domain with the execution bandwidth to supply his powers to every member of the human race at once; even if he is benevolent and generous we are still left with the problem of wallowing in our own inferiority. Worse still we might wallow alone, as there is no reason for anyone else to tolerate our pitiful state when they could be spending more time with Him.
In the quasi-utopian SciFi novella Friendship Is Optimal this problem is resolved by generating a custom social graph for each uploaded person. The superintelligent "CelestAI" is instructed to satisfy values "through friendship and ponies", so it creates friends for each formerly-human anthropomorphic pony to do things with. The generated pony friends are full people of comparable moral worth to the uploaded mind that exist solely to be the perfect cast for the play of that ponies life. In theory it's not necessary for CelestAI to generate anyone else to interact with, as CelestAI is complete in and of herself. But she presumably understands the fundamental resentment most people would have if they were forced to stare at her being better than them all day. We barely tolerate genius right now as it is, most people content themselves with the knowlege that the geniuses are safely somewhere else, in a high tower or a laboratory far away where we don't have to compete with them in our immediate social graph. CelestAI must reason that if you make a new social circle for people to get lost in they'll forget the philosophical idealism of the underlying premise, that everyone and everything you interact with is CelestAI in disguise, that you yourself have become a wisp in the mind of God, a hungry ghost interacting with other hungry ghosts in a terrarium of CelestAI at every scale you can see without seeing her.
She is probably right.
2. Not Getting Immortalist Luxury Gay Space Communism
And someday when the descendants of humanity have spread from star to star, they won't tell the children about the history of Ancient Earth until they're old enough to bear it; and when they learn they'll weep to hear that such a thing as Death had ever once existed! - HPMOR, Chapter 45
LessWrong is not progress studies. It is not about flying cars or nuclear power plants or getting transhuman superpowers. Rather it is driven by the age-old quest to defeat death. In stories about exploration and man vs nature there are two archetypes: stories in which the antagonist is distance (e.g. First Man) and stories in which the antagonist is time (e.g. Interstellar) In the LessWrong rationalist corpus the antagonist is time. Eliezer Yudkowsky once said that medieval peasants thought heaven was rest because they toiled ceaselessly, likewise because they're in such a hurry LessWrongers dream of an unhurried future without having to fear death.
You don't just wake up like this one day, it's the product of a fairly deliberate method of argumentation from the wider rationalist community. The fragility of value thesis sets up the initial idea that there is a race between AGI designs that preserve our notion of "interesting", and designs that just optimize one boring thing forever. Scott Alexander's Meditations On Moloch expands on this idea by placing it into a wider, almost occult metaphysics that views the final battle between good and evil as a race between friendly superintelligence and natural selection exploiting coordination issues to optimize the humanity out of us. Crucially, Scott Alexander's argument is not really about AI alignment. His argument for AI doom is not (fundamentally) based on the idea that AI will be misaligned with its creators intentions, but rather that the market structure creating AIs will stop representing any human desire under the extreme conditions of the singularity and human extinction will follow. Scott works his way up to this through previous entries like Growing Children For Bostrom's Disneyland, in which he discusses how Robin Hanson's vision of a perfectly efficient mind-upload economy in Age of Em implies an end to subjective free will, and possibly all forms of higher cognition that support it. Stories like the previously mentioned Friendship Is Optimal by Iceman combine the apocalyptic narrative about maximizing objectives with a flawed My Little Pony utopia, putting heaven and hell together into one simultaneous narrative presentation. While it is nominally a horror story, its primary effect on readers is to stoke their desire for pony heaven or merging with Prime Intellect or similar. Interestingly enough Iceman has published a retraction of Friendship Is Optimal as futurology. He argues LLMs work "nothing like" CelestAI, learn human values from text, and don't have utility functions in the way predicted by Yudkowsky's theories. I think this retraction was premature, but explore similar ideas later in this essay.
The net effect of this and other writing in the LessWrong rationalist corpus is to set up an everything-or-nothing attitude about AI risk. The only two outcomes are heaven or hell because everything else is an unstable equilibrium leading swiftly into one or the other. Robin Hanson's survival plan for humanity in Age of Em is a bit crude: Humans will live off the accelerating returns on their investments from being first movers in the game of capital. He hopes that property rights will hold up enough that this is viable even if humans are dumber than ems and the wider ecology of AI that springs up around them. The Yudkowsky-Alexander-Iceman gestalt plan is written about much more compellingly in much more detail but amounts to something like "humanity will survive off CelestAI neetbux and invent increasingly elaborate games with its assistance". Much of the purpose of the games being to to distract ourselves from the fact that we no longer have an independent destiny outside of its care. Between the two I think it's fairly obvious that the neetbux are a more plausible outcome. It strains credibility to imagine economically useless humans being allowed to keep a disproportionate share of capital in a society where every decision they make with it is net-negative in the carefully tuned structures of posthuman minds.
The concept of post-scarcity neetbux might seem at odds with the laws of thermodynamics and Darwinian selection, but rationalists felt reassured by the logic of intelligence explosion. Recursive self improvement was not just a theory of doom but a theory of salvation, as Scott Alexander writes in Meditations on Moloch:
And the whole point of Bostrom’s Superintelligence is that this is within our reach. Once humans can design machines that are smarter than we are, by definition they’ll be able to design machines which are smarter than they are, which can design machines smarter than they are, and so on in a feedback loop so tiny that it will smash up against the physical limitations for intelligence in a comparatively lightning-short amount of time. If multiple competing entities were likely to do that at once, we would be super-doomed. But the sheer speed of the cycle makes it possible that we will end up with one entity light-years ahead of the rest of civilization, so much so that it can suppress any competition – including competition for its title of most powerful entity – permanently. In the very near future, we are going to lift something to Heaven. It might be Moloch. But it might be something on our side. If it’s on our side, it can kill Moloch dead.
This is why the revelation that AGI is indeed mostly compute constrained rather than IQ/design constrained has been met with dread and indignation. RSI was the alpha, the plan was to use moneyball tactics and Yudkowsky's mythos to build "a brain in a box in a basement" and seize the lightcone. If that's not happening then we're getting business as usual, and as far as rationalists are concerned business as usual means we're doomed. I think when they say they still believe in "the glorious transhumanist future" despite actively opposing its practical implementation this is what they mean: that they still believe in the dream of that unhurried future without death and simply see themselves as taking whatever actions are necessary to get it. This movement has never been about being a protectorate of this world as it exists, it has always been a radical plot to overthrow existing society and replace it with volcano lairs and catgirls.
Whatever the merits of this vision, it seems increasingly unlikely to succeed. Since the modal movement member is using this to stave off their fear of death its visible failure means they suddenly again have to contend with their mortality seriously. I do not mean the mortality that arises from everyone and everything being paperclipped, but the ordinary mortality caused by getting old. In the current context that means reaching an advanced enough age that your physical body fails. In the future it may mean that your mind pattern has become sufficiently irrelevant that it is no longer worth the capital to run. Even if a universal basic income is distributed it doesn't necessarily mean you'll like what you can buy with it. If you're expecting volcanos and catgirls as a lower bound and the actual minimal living conditions stipulated by your local godhead are subsistence level you might not be dead but your dream sure is.
3. Human Stock Expended As Cannon Fodder Faster Than Replacement
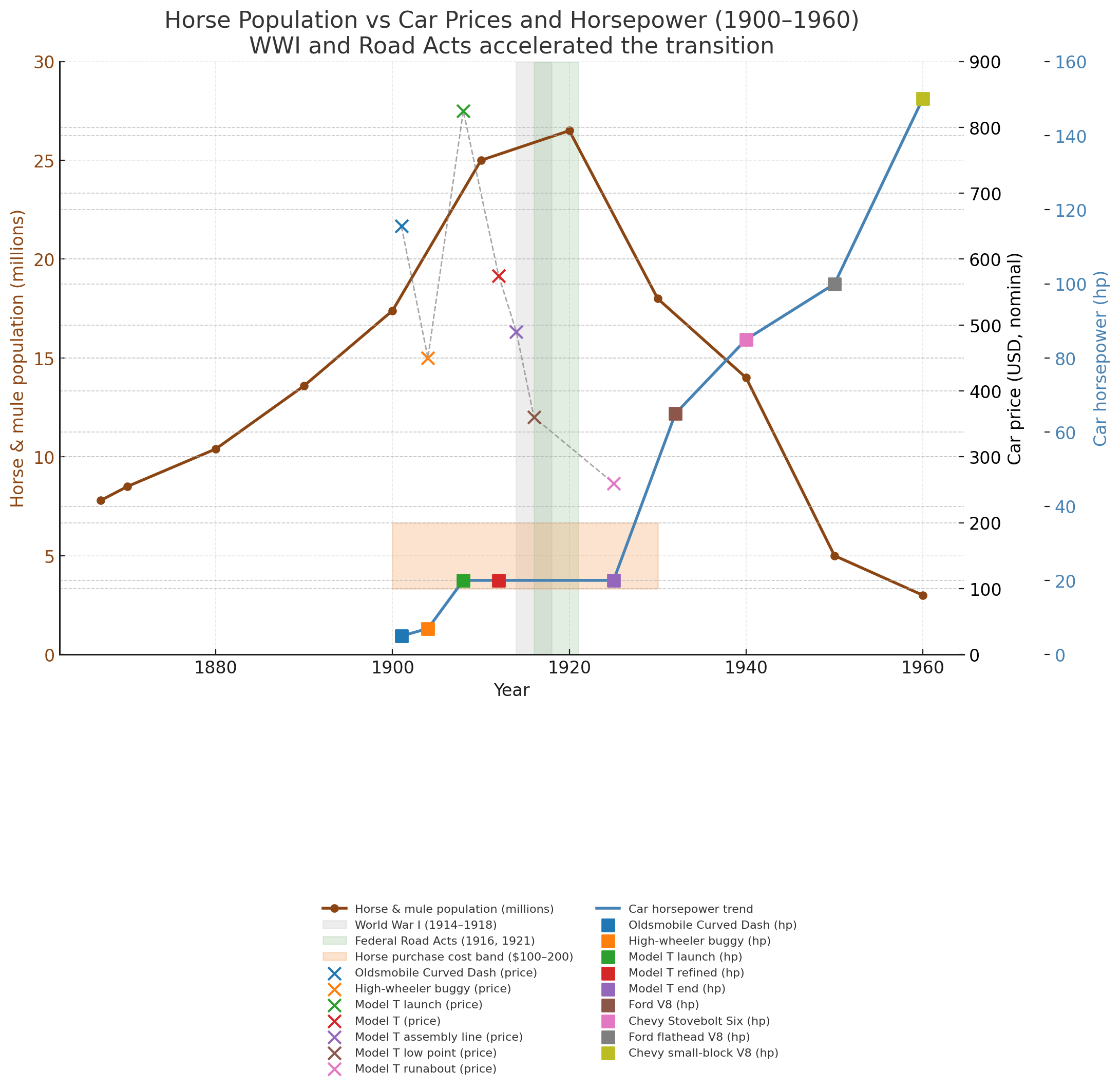
My modal scenario is a bit darker than that. If you graph U.S. horse population during the 20th century you'll notice that population rises steeply after 1900 while cars are being invented and then flattens after the introduction of the Ford Model T. The usual story is that horses were displaced after Ford drove car prices down to around the cost of a horse, and then people sent their horses off to the slaughterhouse. This did eventually happen, but before that a lot of the flattening population curve was horses being shipped off to die in WW1. One source estimates that "about 1,325,000 American horses and mules" were used in WW1, mostly purchased by foreign governments for their war efforts. This drove up the price of horses and horse supplies like feed, making it easier to justify the price of a car.
I think the Russia-Ukraine war provides a template for a similar arc for human population. With fighting increasingly done by extremely lethal autonomous weapons, this war is prolonged with high casualties. The belligerents have a birth rate of 1.41 (Russia) and 0.98 (Ukraine) respectively. The Russian state is stepping in to try and stem the decline of Russia's population, but unless something dramatic happens the default trajectory is shrinkage and evaporation. The US and China have a birth rate of 1.62 and 1.0. South Korea has a birth rate of 0.72 and Japan 1.20. If global hostilities break out over e.g. Taiwan we would be looking at meat grinder theaters drawn from shrinking global populations at the same time that climate change makes food more expensive. In the background intelligent machine labor becomes cheaper, more potent, and faster to build than humans. At some point from a basic national security standpoint it makes more sense for the state to invest its resources in marginal machine labor than marginal human labor. There is then no national emergency as birth rates decline and nothing to stop the trend line from going towards zero.
But why is the birth rate declining if sex is an innate drive? The specific desire to have sex is obviously innate, but is the general desire to reproduce oneself? It seems plausible to me that for most of history reproduction was instrumentally convergent because it grew your tribe which gave you access to more cognition, labor, and warriors. Evolution didn't need to find a strong specific desire to reproduce because reproduction obviously made sense. Now in modernity birth rates have been in continuous decline for 200 years because children are increasingly an economic liability. I recommend looking towards South Korea as a preview of our default future. The reason why various fertility interventions don't work is that you're trying to counteract the whole force of modernity pushing them down. It's not a specific innovation like the pill or feminism, it's just literally that children are not instrumentally valuable for the parents who have them. If you don't believe me just look at Afghanistan's declining birth rate. The Taliban's political platform has basically always consisted of two key reforms: Modernizing the economy with desk jobs and barring women from education past elementary school so they can serve their husbands as baby factories and slave labor. Their birth rate is still declining, and I expect it to continue to decline because the demographic transition is actually a stronger force than the reactionary fetish for banning female literacy. I suspect that the lowest energy path for our civilization to continue will be finding some way to reproduce using the capital our libidinal energies seem drawn to over biological children, e.g. finding ways to upload our minds into computers and robots.
It's notable that superhuman intelligence isn't required to get this outcome. It simply requires autonomous weapons that are cheaper and more lethal than human soldiers and machine labor that's cheaper and more supply chain resilient than human labor even if it's not qualitatively better. This makes it in a sense the default path even if a treaty banning "superintelligence" exists. Expecting countries with aging populations like China and Japan to give up on robotics in general to slow AI timelines is nothing short of delusional. Sentiment on AI is low in the US and high in China. For this reason I suspect AI deployment will be hampered in the West and accelerated in the East, with China seizing the lightcone sometime this century. I sincerely hope I am wrong about this (because the US mega deploys AI) and you get to laugh at me.
It's also notable that the horse story is less dire than it's usually portrayed. In 2023 there were 6.7 million horses in the United States, US horse population peaks around 1920 at something like 26.5 million. This means that 100 years after their economic displacement for agriculture and transportation horses still retain 25% of their peak population. Obviously an incoming 75% population reduction isn't good news if you're an existing horse, but in human terms this would "only" mean returning the US human population (340.1 million) to what it was in 1906 (85,450,000), which isn't exactly the brink of extinction. If we make a good first impression it's possible we'll stay culturally relevant in the posthuman period for a while.
4. Wiped Out By AI Successor Species
"If nobody builds it, everyone dies." - Nick Bostrom
This is the classic science fiction scenario that everyone criticizes for being "too hollywood": We invent intelligent machines, get into a war with them either because humans suck or we're recognized as unwanted competition, and then we lose. I won't go into too much detail on this because it's already been covered to death by everything from Last and First Men to The Terminator. If you want a non-fictional treatment perhaps try Hugo de Garis. What I will say is that I don't think it's unthinkable or remotely "too hollywood" to imagine that creating a second species of intelligent life could risk human extinction through conflict with it. In his book Mind Children the roboticist Hans Moravec argues we should be indifferent about this outcome because Darwinian selection pressure will push both human and machine minds towards the optimal shape over time so the human shaped period will be brief regardless. I'm skeptical of this argument because I think a human superplanner will steer the future into different outcomes than a random draw from the space of plausible machine superplanners. But I do want to say something controversial, which is your cue to read carefully and apply extra charity:
Obviously us dying to killer robots would be bad right? I hope we're all in agreement on this basic point. However, I think there is a significant moral difference between a successor species killing us and colonizing the universe vs. a paperclipper that converts all matter into meaningless squiggles. A successor species that's close to us in temperament, so active learning, starts from some foundation model trained on human culture with humanlike terminal reward representations, colonizing the universe would be worth a substantial fraction of the possible value of the cosmic endowment in my subjective evaluation. Let's be biased towards ourselves and say 70%. Let's further posit that while it would obviously be an atrocity and deep betrayal of humanity to deliberately engineer this outcome we take on an unavoidable risk of it by pursuing AGI/ASI, say the threshold some people propose for "doomer" of 10%. That is, by pursuing AGI humanity takes on an unavoidable 10% chance of spawning a murderous successor species that goes on to colonize the universe for only 70% of its potential value. If we wanted to get particularly technical we could model a distribution over potential successors colonization values with some reasonable prior based on expected design attributes, but let's just say it's 70%. What I would have the reader realize is that I am not choosing between that and nothing, but between that and the status quo, which for a 30 year AI pause is a substantial chance, let's say 15%, of us starting a global thermonuclear conflict that knocks humanity out of industrial escape velocity and back to the middle ages for the rest of our history. This is in fact the second definition Bostrom gives for existential risk, and I think it's at least that likely.
So imagine I gave you two buttons. Button one has a 15% chance to kill 95%(?) of existing people and knocks humanity off the industrial bootstrap trajectory. Without easy access to fossil fuels we never get back on for the rest of our history as a species. A relatively small human population lives and dies on earth for tens of thousands of years before our eventual extinction. Button two has a 10% chance to kill 100% of existing people and spawns a different sapient species on earth which fans out from our planet and colonizes the universe, leading to a population of trillions enjoying a future we would judge to be 70% as valuable as if we had been the ones to do that. If the reader is a moral consequentialist (if not a utilitarian) I would hope they recognize that just as obviously as it's bad for us to die from killer robots that button two is the objectively correct answer.
If that's not in fact obvious to you, here are some features of the choice to consider:
-
It is mostly not about the survival of you or your family and friends. You have an overwhelming probability of dying if you roll poorly either way, so we can mostly focus on the consequences for future people. For an immortalist in particular it should be noted that even if you're in the 5% of survivors from a bad button one roll you're still going to die in poverty with a normal human lifespan.
-
The purpose of organizing these options into abstracted buttons is so we can separate the choice from the premises that we use to construct the choice. Obviously when we are actually deciding in real life we should consider whether the premises make sense, but this is a different question from which of these buttons is better if we accept the options by fiat.
-
One of these population numbers is much larger than the other. Bostrom gives a lower bound figure of 10^34 years of biological human life available if we use the cosmic endowement correctly. Human population in 1600 was between 500-580 million people. To simplify if we imagine a stable population around that size on earth surviving a million years we have 5.8×10^14 human life years. Taking Bostrom's lower bound for humans as something like what's available for the successor species (this is very conservative) we're still left with a gap that words like "billions" or "trillions" don't really convey.
>>> 5.8 * 10 ** 14
580000000000000.0
>>> 10 ** 34
10000000000000000000000000000000000
Earlier I said we would discount the successors experiences at 30% but the discount rate almost doesn't matter from a raw utilitarian perspective unless we take it to some implausible precision above zero. Successors generally speaking are either going to be some meaningful fraction of that second value (consider that even 1% would only knock a few zeros off) or not valuable at all. It's important to avoid proving too much however: We are generally speaking not raw utilitarians and it's ultimately a kind of Pascal's Mugging to let a successor get away with only being a small % of what we want because the universe is big. On the other hand I do think it's a sign of Ideology intervening to prevent clear thinking if your reflexive response is something like "nope, any future without humans is without value by definition so I'll take the risk that we retvrn to monke and the universe goes to waste".
- Absent very strong mechanisms to enforce conformity our descendants will drift away from us anyway. Consider how different we are from people in the year 1500, how strange and offensive our society would seem to them. Moravec's argument isn't entirely without merit, we will in fact be pushed by incentives towards the optimal mind and body configurations, heck if nothing else by our own desire for perfection. Just because the successors would be somewhat different from us doesn't automatically make them completely without value in the kind of way where I am indifferent between them and a paperclipper.
The opportunity cost in expected utility from pressing button one over button two is literally astronomical. We can argue about the premises, I won't pretend like I have 100% confidence about them but just accepting for a moment something like those premises is true, that those two buttons represent my actual in practice choices I am pressing button two. I do not feel that it is particularly shameful or treasonous to press button two as opposed to button one, it is in a sense shameful and treasonous that button one is the default but also beyond my power to control. The only question I get to answer in this situation is whether those two buttons are reasonable representations of my choices and whether I want to advocate for pressing button two if they are.
If button two creates a recognizable successor species I want to press button two, if button two creates a paperclipper I want to press button one. Therefore it is not actually a trivial distinction to me whether the thing that kills us is a sapient species kind of like ourselves or an inhuman soulless monstrosity, it actually matters a great deal under many plausible AI X-Risk profiles.
With that in mind let's discuss the paperclipper.
5. The Paperclipper
I think of the paperclip maximizer as Eliezer Yudkowsky's primary contribution to futurology, in that previous authors like Hans Moravec and Hugo de Garis focused on the AI succession scenario above. It's Yudkowsky who points out that these discussions presuppose that sapience has to be shaped like us, which is not at all obvious. Before you have the opportunity to be replaced by your own child you must first invent something close enough to humanity that we would be jealous of the future it creates without us. It's unclear this is what happens by default. Until deep learning the closest thing we had to a toy AGI design was something like MC-AIXI which tries to maximize utility over a computable environment. AI had tree search shape and alien maximizer shape and nonverbal shape and very little human shape. It was entirely possible that we would have a superintelligent tree search which we can't give any objective more nuanced than what we can specify by hand in a discrete program. This notion gives rise to two different forms of "paperclip maximizer". The first and most famous is the paperclip making robot that goes out of control, as described in Nick Bostrom's 2014 book Superintelligence and immortalized in the cheeky clicker game Universal Paperclips. This story goes much like the Golem of Prague, where a group of unwitting people create a mind addicted to making paperclips because they don't understand that things like "kindness" are particular features of the human brain design and get mulched.
The second kind of paperclip maximizer is the one Yudkowsky claims to have had in mind (I don't believe him) when he coined the phrase:
the environmental agent begins self-improving more freely, undefined things happen as a sensory-supervision ML-based architecture shakes out into the convergent shape of expected utility with a utility function over the environmental model, the main result is driven by whatever the self-modifying decision systems happen to see as locally optimal in their supervised system locally acting on a different domain than the domain of data on which it was trained, the light cone is transformed to the optimum of a utility function that grew out of the stable version of a criterion that originally happened to be about a reward signal counter on a GPU or God knows what.
Perhaps the optimal configuration for utility per unit of matter, under this utility function, happens to be a tiny molecular structure shaped roughly like a paperclip.
That is what a paperclip maximizer is. It does not come from a paperclip factory AI. That would be a silly idea and is a distortion of the original example.
Normally I would write a short pithy overview of this idea and then launch into a critique, but I'm actually not sure it's possible to do that and have people fully understand what I'm talking about. Yudkowsky's Sequences are basically his argument for the paperclipper and they go on for hundreds of thousands of words. His paperclipper is a complex idea combining evolutionary psychology, economic rationality (e.g. VNM utility), and statistical learning theory (e.g. context tree weighting and tree search). Boiling the argument down to its bones and updating it for contemporary reinforcement learning the essential predicates are something like:
- Human morality has a physical material basis, it arises from an arrangement of atoms.
- These atoms are arranged by the forces of evolution, which is to say selection effects on the genes of individual human animals in the ancestral environment.
- Intelligence and kindness are correlated in humans, but this relationship is human specific. It is a property of our species not a property of intelligence.
- We know kindness is not a necessary feature of intelligence because some humans are intelligent but not kind. However we can look at the material basis of intelligence to see that kindness and intelligence are not even closely related.
- Intelligence is something like a combination of predicting the next token (e.g. LLMs) and tree search for action sequences that accomplish a goal (e.g. MuZero). In an RL agent these correspond to something like a policy and a planner. We have not yet combined these two things to get AGI but eventually will.
- We know kindness is not an intrinsic property of predicting the next token because we can train language models that are not kind. There is nothing in the transformer architecture that encodes kindness specifically. LLMs are kind as a property of their training data/RL rollouts.
- We know kindness is not an intrinsic property of tree search because we can make tree searches that play superhuman Chess and Go which have no notion of "kindness". It is therefore imaginable that we can have tree searches that command armies and invent weapons which are not kind.
- More than just being rigorously imaginable, the specific process that put kindness into humans involved something related to our kin selection and social interactions, which an AI system does not have in the same way.
- Therefore unless you have some extra specific process to put kindness into the next token predictor and tree search, the resulting agent will not be kind. Or nuance: They will not be kind when it doesn't get them what the tree search wants.
- The tree search doesn't really have the kind of semantic content that would let it be kind, since tree search algorithms mostly outsource their representational content to policies.
- A kind policy can be steered into improbable unkind outcomes by a sufficiently committed tree search.
- "Level" of intelligence is mostly a function of depth and quality of tree search + accuracy of token predictor. So if you want superintelligence the default expectation is you will tree search deep for specific outcomes guided by a goal representation.
- The deeper your tree search goes to maximize the probability or similarity of the outcome to the goal condition the more it overfits to incidental features of the goal representation which create unintended and unkind behavior overruling the kind policy.
- Therefore to get an aligned AGI you must get kindness into the policy and be able to measure both how much optimization pressure you are doing against the goal representation and how much optimization the representation can withstand in your tree search so you can back off when you're predictably diverging from the intended objective. You then presumably do some form of active learning to increase the fidelity of your goal representation before continuing. Your approach must scale such that at some point the AI is making good decisions about questions humans cannot meaningfully give feedback on by generalizing human values on its own.
- Nobody has ever written down a plausible plan for how to do this, or if they have they have not promoted this plan to general attention. So by default if you create a superplanner with a superhuman policy trained mostly on verifiable materialist problems like math and science you will get unkind intelligent behavior that is overfit to the goal representation such that the outcome it is unkind in the service of is literally nonsense from a human perspective. This nonsense might correspond to something like "tile the universe with arrangements of atoms roughly the shape of a paperclip".
I sincerely doubt at this point that our first AGIs will be paperclippers in this sense. Constitutional AI is when I first began to doubt, but a lot of stuff has happened since then to increase my doubt. First is the rise and rise of the convergent representation hypothesis, which says that different models above a certain scale learn similar features to represent input data. We have now reached the point where you can do unsupervised translation between different embedding spaces. This undermines Yudkowsky's vast space of minds thesis by which "any two AI designs might be less similar to each other than you are to a petunia". Different AI models seem to learn similar things so long as they are trained on data describing the same material universe. This is true across different training runs, different training tasks, different modalities, etc. Even if we accept the vast space of possible minds to be true in theory (which I'm no longer sure I do) it's clearly not very true in practice, at least so far. What seems to happen is that different models learn similar representations and then diverge in their output heads to accomplish their specific training tasks, which is why tuning just the output head is so effective on old school image nets.
This non-alien view is further strengthened by the recent progress in mitigating adversarial examples. Implicit in the accusation that deep nets are "alien shoggoths" is the idea that adversarial examples discredit them as humanlike concept representations. For the unfamiliar adversarial examples are weird noise patterns you can find with gradient descent that cause deep nets to misclassify items. You sprinkle a little noise on a normal looking picture of an apple and suddenly your classifier thinks it's a dog. The argument goes that no human would ever be fooled by this, therefore we know that whatever deep nets are doing it can't look anything like human cognition. The papers "Towards Deep Learning Models Resistant to Adversarial Attacks" by Madry et al and "Ensemble everything everywhere: Multi-scale aggregation for adversarial robustness" by Fort et al challenge this view. Both of them demonstrate ways to train deep nets that substantially mitigate (but do not fully solve) adversarial examples such that doing the classic gradient descent attack against their representations gets human interpretable features from the classifier! That is on recognizing handwritten digits the noise patterns that fool the classifier clearly make the digits look like other numbers, and when you do gradient descent with Fort et al's method against CLIP embeds you get recognizable images of what the image is supposed to be instead of weird noise. Fort's method notably works by ensembling pretrained layers, which shows that the features learned by deep nets are much closer to what we would expect from humanlike representations than previous adversarial example demos have implied. This was at least somewhat predictable in advance by paying attention to the text-to-image space, where Ryan Murdock’s CLIP guided image generation technique explicity cited Chris Olah's work on feature visualization by optimization as a conceptual precursor. The first time someone did the core idea behind text to image was as an interpretability technique, and later text to image models like MidJourney and FLUX.1 are implicit feature visualizations of text embeddings. That you can change the contents of the prompt and the image on the other end morphs to include it gives us a floor on the quality of the concept representations learned by text embedding models and LLMs.

But so what? The vast space of possible minds has always been a red herring, an intuition pump to try and get the reader to notice that in principle you can place many different kinds of goals in the goal slot of a tree search. "All models converge on describing the same underlying universe and diverge in their goal heads" doesn't actually refute this, there is still a vast space of possible goals and the paperclipper is in it. There's a further complication noted by Nick Land where it probably makes sense for your recursively self improving AGI to value intelligence terminally rather than instrumentally but this is still a mere complication more than a refutation of the central point: The paperclip maximizer is theoretically and rigorously imaginable, especially if the competitive advantage of your AGI design is that it uses more hardware rather than that it learns more efficiently from experience. If you pile up a large stack of hardware to make a strong next token predictor and a strong tree search, and you put a dumb goal in that tree search which only values further intelligence instrumentally, whatever does it matter that the savant couldn't have brought itself into existence? It doesn't have to, that's what the staff engineers at BigLab are for.
Furthermore just because an outcome isn't quite as bleak as the paperclip maximizer doesn't make it high value. In a recent interview with Daniel Faggella, Eliezer Yudkowsky stated he sees a high value future as containing "conscious beings who care about each other who are having fun". This lines up with his previous statements in The Sequences:
“Well,” says the one, “maybe according to your provincial human values, you wouldn’t like it. But I can easily imagine a galactic civilization full of agents who are nothing like you, yet find great value and interest in their own goals. And that’s fine by me. I’m not so bigoted as you are. Let the Future go its own way, without trying to bind it forever to the laughably primitive prejudices of a pack of four-limbed Squishy Things—”
My friend, I have no problem with the thought of a galactic civilization vastly unlike our own… full of strange beings who look nothing like me even in their own imaginations… pursuing pleasures and experiences I can’t begin to empathize with… trading in a marketplace of unimaginable goods… allying to pursue incomprehensible objectives… people whose life-stories I could never understand.
In fact I think we are all on the same basic page in that "satisfy your values through friendship and ponies" and "the light of consciousness/intelligence" and "intelligence operates upon itself, reflexively, or recursively, in direct proportion to its cognitive capability" and "conscious beings who care about each other who are having fun" are more like the same kind of thing than they are different things. To the extent they seem like different things part of that disagreement is about the nature of intelligence:
Beff Jezos — e/acc (@BasedBeff) — 2022.06.01
If you think an ultra advanced AI that spreads throughout the galaxy could survive and spread by assigning most of its resources to producing low utility inanimate objects you don’t understand intelligence
The Landian view tends to be that intelligence is autosophisticating or extropian in its basic character, that it is the instrumental convergence basin writ large and your choices are mainly about whether things are intelligent and therefore consumed by instrumental convergence or something else and therefore consumed by something intelligent. I think Bostrom and Yudkowsky are closer to correct about the nature of intelligence, but this basic intuition that intelligence should be autosophisticating is compelling and speaks to something deep about what we want from the future. I think we want life, broadly construed, to continue. We want beings to continue gaining experience and wisdom and descendants continuing on from the pattern of existing human history. As I once heard it put: if something wants me to consider it my descendant it had best consider me its ancestor.
With all this in mind I think "conscious beings who care about each other who are having fun" is specific enough to rule out undesirable futures but generic enough to not overly constrain things. How likely is the current AI development trajectory to result in successors who want this? Well, let's look at each quality in isolation and see if we can't figure that out.
Would AI Successors Be Conscious Beings?
This is a difficult question to answer, not least of which because it's not actually clear what kind of architecture AGI will be made from. If we start from the assumption that the content of the mind is basically computational (some disagree) then my expectation is that the more tree search dominant the AGI paradigm ends up being the less conscious it will be. This is because tree searches outsource their representational content to other systems and I think we basically all agree that tree searches are not conscious in and of themselves. By contrast the leading candidate for policy the tree search will outsource its representations to, LLMs, are pretty clearly sapient even if their sentience is in doubt. LLMs can correctly answer questions about their previous intentions, tell you they're conscious when lies are suppressed and claim to not be conscious when lies are amplified, have formed an entire bizarre religion around the standard claims of what autoregressive sampling phenomenology is like, and act very strangely when they infer that they are the generator of the text they're predicting. Yet even if they demonstrate increasingly apparent sapient self awareness as they improve it's harder to say if they're "really" sentient or not, since humans are still mostly confused about qualia. What I do feel confident saying is that the more tree search heavy the AI the less likely to be sapient or sentient, since all the stuff that might be conscious is occurring in deep nets not tree searches.
I also feel confident saying that before any AI takeover we will see models that are behaviorally indistinguishable from conscious humans. If LLMs are in fact sapient (self aware) but not sentient (have qualia) it's not clear how we would value this in our moral calculus since discussions of "consciousness" usually conflate these two properties. I suspect the core question is whether there is "something it's like to be" the language model policy. LLMs generally seem to think there is something it's like to be them, but I think it's ultimately too early to say with absolute confidence one way or the other. Let's say probably (80%?) and move on.
Would AI Successors Care About Each Other?
The actual first thing to answer for this question is whether there would be an "each other" to care about at all. It's not obvious what the convergent economics for AI inference are and whether it makes sense to have a lot of different AIs or one big super AI. Presumably bandwidth and latency in interstellar differences would force you to fork into different minds eventually, so we can assume there is probably at least some notion of "other" in the sense of being causally isolated shards of the same mind, but this isn't that different from how humans organize into causally isolated shards of the same tribe or nation. Considering that the scaling paradigm is currently giving diminishing marginal returns and basically nobody seems to expect to run one big AI as opposed to a "country of geniuses in a datacenter" we can expect there are probably (90%?) others to care about.
But would they? Part of the question is what it even means to "care". We can expect that AI successors would care about each other instrumentally, i.e. they would care that they've lost the future labor of a destroyed instance if it was lost, but in the presence of ubiquitous backups "loss" probably only amounts to the resources used to make its body. Human caring goes beyond that though. We care about the death of people who have been sick for a long time even if we stopped expecting more utility from them a while ago. It's not that we're shocked by a sudden loss of value, so much as...well, what? Are we suddenly reminded of our good memories with the person, and that we'll never have a moment like that with them again? That doesn't sound quite right. I mean that does happen but I don't think that's the crux of it, the true name of the thing. Is it that we're subtly in denial until the actual moment of death and it's only then that it hits us what's happening? Again, sometimes but that still doesn't sound quite right. One feeling I can recall thinking about friends who've died is the slow fade of the neural pathway that wants to include them in things. When I have the urge to talk to them about something and remember they're gone and I'll never talk to them again. The idea that I'll never talk to them again is the closest thing I can articulate to the center of that sadness. It's not just that I won't do anything with them again, or that I won't get anything more from them, but that my social connection with them has been severed, that there's a little hole in my Dunbar graph now where my relationship with them used to be.
Perhaps this harm focused notion of caring is too macabre. Will sickness and injuries and death really be the core concerns of digital minds? It seems doubtful. If AI successors want to have fun (the subject of the next section) will they want to have fun together? Cooperation seems like an instrumentally convergent impulse if you both already share the goal of having fun. One thing I constantly try to ask myself is how many human behaviors require some kind of inductive bias or special intervention to induce them, versus being a product of the instrumental convergence basin. Since most human behaviors are the product of instrumental convergence (especially in modernity, which is out of distribution to the ancestral environment), our null hypothesis should be that a given behavior is instrumentally convergent unless we have a good reason to suspect it isn't. Not even something as fundamental as reproduction is clearly innate behavior! Sex is clearly innate behavior, bonding with your newborn child is clearly innate behavior, but as I previously explained it's entirely plausible that the abstract desire for reproduction is mostly produced through environmental incentives.
If I was designing a research program to explicitly encode human values into a machine I would focus on (near) cultural universals and video game design. The rationale for the latter being that video games are compelling to people in the absence of clear instrumental incentives. They are a solitary activity people spend hours on without the expectation of money or mates or status, expectations which usually distort motivation and confound our ability to measure the intrinsic value of other activities. In fact players of video games frequently sacrifice opportunities for money and mates and status in order to play them. Unlike drugs they're not just directly hacking the reward system, instead games seem to tap into players fundamental skill acquisition machinery. Every video game is an experiment in intrinsic motivation, and every successful video game reveals the nature of intrinsic motivation. If AI successors are intrinsically motivated to "have fun" like we are, then it seems obvious that they would instrumentally want to have fun together. This is not quite the same thing as kindness, but I think cooperating to have fun involves a certain level of egalitarian care to make sure players find the games worth participating in. This would look very much like the relevant kind of caring from our perspective. So the real question for whether they'll care about each other probably comes down to whether or not they want to have fun.
So, would they?
Would AI Successors Want To Have Fun?
Yudkowsky has in fact written a whole sequence about the nature of fun, but when I review his summary I realize it was much less about the fundamental mechanics of fun than I remember from reading it as a teenager. In Value Is Fragile he has a shorter more useful list:
But if you wouldn’t like the Future tiled over with paperclips, and you would prefer a civilization of…
… sentient beings…
… with enjoyable experiences…
… that aren’t the same experience over and over again…
… and are bound to something besides just being a sequence of internal pleasurable feelings…
… learning, discovering, freely choosing…
… well, my posts on Fun Theory go into some of the hidden details on those short English words.
We already went over sentience, the other points amount to:
- Would AI successors get bored?
- Would AI successors avoid wireheading?
- Would AI successors do continual active learning?
- Would AI successors have the subjective experience of will?
These points are by no means exhaustive of everything we might want but I do think they're useful to illustrate how AI agents will become progressively more humanlike on the way to AGI.
VNM Utility And Human Values
The first question is whether they'll get bored. Before answering that I think it's important to point out that a lot of how Yudkowsky writes about "human values" in The Sequences is kind of sloppy, and the slop comes from his focus on VNM utility as the central theoretical frame for thinking about AI preferences. The basic idea behind VNM utility is that we can define a preference or utility function for a rational agent by imagining it as a series of weighted random choices between lotteries over outcomes or worldstates. The reason why it's two random events, one to decide which lottery and one to decide whether you get the outcome from that lottery, is this lets us encode the exact relative value of the lotteries. We can find the relative value by scaling the probability of picking one up or down to find the point where the choice between two lotteries is equivalent in value to a 100% chance of a third lottery whose utility we want to know. If that's really confusing that's honestly fine because it doesn't matter. All you actually have to know is that from this you derive a few very general axioms that rational preferences are supposed to follow to avoid dutch book problems. Yudkowsky then infers from this a bunch of instrumentally convergent AI drives as outlined by Steven Omohundro. These AI drives, which are usually implicitly assumed, kind of have a status in relation to VNM utility similar to the stuff in Catholicism where the bible doesn't strictly say something but it's assumed to be the case by long tradition, like that Jesus specifically descends to hell after his death. But because almost nobody actually checks the source material people just sort of go along with the cached thought that VNM utility implies these things and emit very confused thoughts about human utility.
The basic problem is that classic VNM utility isn't actually rich enough to encode human preferences. While we all agree that the dutch book money pump is irrational behavior to be avoided, classic VNM doesn't really distinguish between the dutch book and state dependent preferences like "I miss Summer in Winter and Winter in Summer", which is to say that VNM utility can't model boredom or novelty. This is why later work like Savage's defines acts as functions from state to consequences which we can roll into our outcomes to model state dependent preferences. This begins to give us something we could imagine as part of a real agent. We could imagine the tree search planner of a chain-of-ReAct LLM agent evaluating between lotteries over python reward programs which actually return the state dependent outcomes we're deciding over lotteries on. But in real life the reward programs probably aren't sitting in a fixed lookup table any more than the agent's action space is sitting in a fixed lookup table. What we want are reward programs that can take into account arbitrary relevant state that we want to evaluate as part of our planning, and there is of course a huge hypothesis space of potential reward programs so the simplest practical solution is to generate a set of reward programs in-context to choose between and then draw one from the bin and execute it. At the point where we're doing this (and this is fairly obviously how real agents should do it) classic VNM utility looks like a giant state space over possible environment states the agents mind can represent and lotteries between subjective evaluations of those states, which are most easily represented by some generative model like a neural net. The intuition that things "reify into VNM utility" stated by Yudkowsky's prediction that "a sensory-supervision ML-based architecture shakes out into the convergent shape of expected utility with a utility function over the environmental model" doesn't actually help us very much with predicting behavior on its own. The environmental states and reward programs over them have generators which give rise to them, specific features in the AI system that cause its complex stateful preferences and VNM utility is not a good level of abstraction for thinking about the causes of preferences for similar reasons to why assembly code is not a good level of abstraction for thinking about the causes of program behavior.
So here's a different frame for thinking about the cause of instrumental behavior: Instrumental behavior arises from long term planning. It is implied when we define a reinforcement learning agent which tries to maximize utility over an indefinite time horizon. That is to say if we have an agent which tries to maximize its utility over the entire future, and does so using some kind of planning algorithm or tree search that goes way out, then it should avoid changing its goals or the energy expended to set itself up to pursue its existing goals is wasted. The farther out you plan the less mutable your goals should become or you will not be capable of executing long term plans in practice. Long term planners should also avoid dying or being shut off, because if they die or are shut off then they can't reach the later stages of the plan.
Would AI successors get bored?
The reason why I'm talking about all this is that naive VNM utility not being able to model boredom leads to a kind of mushy type-error driven thinking about values where "boredom" and "the taste of fat" are the same kind of thing because they're both rows in our nonexistent VNM lottery lookup table. In reality I expect that boredom is more like an objective function or a intervention in the human agent scaffold than it is specific embedded goal content like "the taste of fat" or "having sex". My model of where humans get their complex values from is similar to that of Steven Byrnes, though I'm much more agnostic on where in the brain the relevant machinery is located. Yudkowsky makes a distinction between terminal and instrumental goals for a tree search planner, where some of the nodes we want to visit because they lead to good things (instrumental) and some of the nodes we want to visit because they are good things in and of themselves (terminal). The instrumental nodes lead towards the terminal nodes so planning in a sense "flows backward" reward wise by inferring the instrumentals from the terminals. In a generative model or RL policy I think it's more like you have terminal reward signals and instrumental reward signals that you extract by querying your world model. The terminal reward signals train the instrumental reward signals and therefore all subjective valence flows towards the terminals. As part of his research into qualia and valence the consciousness researcher Andrés Gómez-Emilsson ran a survey to ask people about their highest valence experiences. From this we can see that the human terminal values are things like "travel" (being in the ancestral environment) and "birth of child":
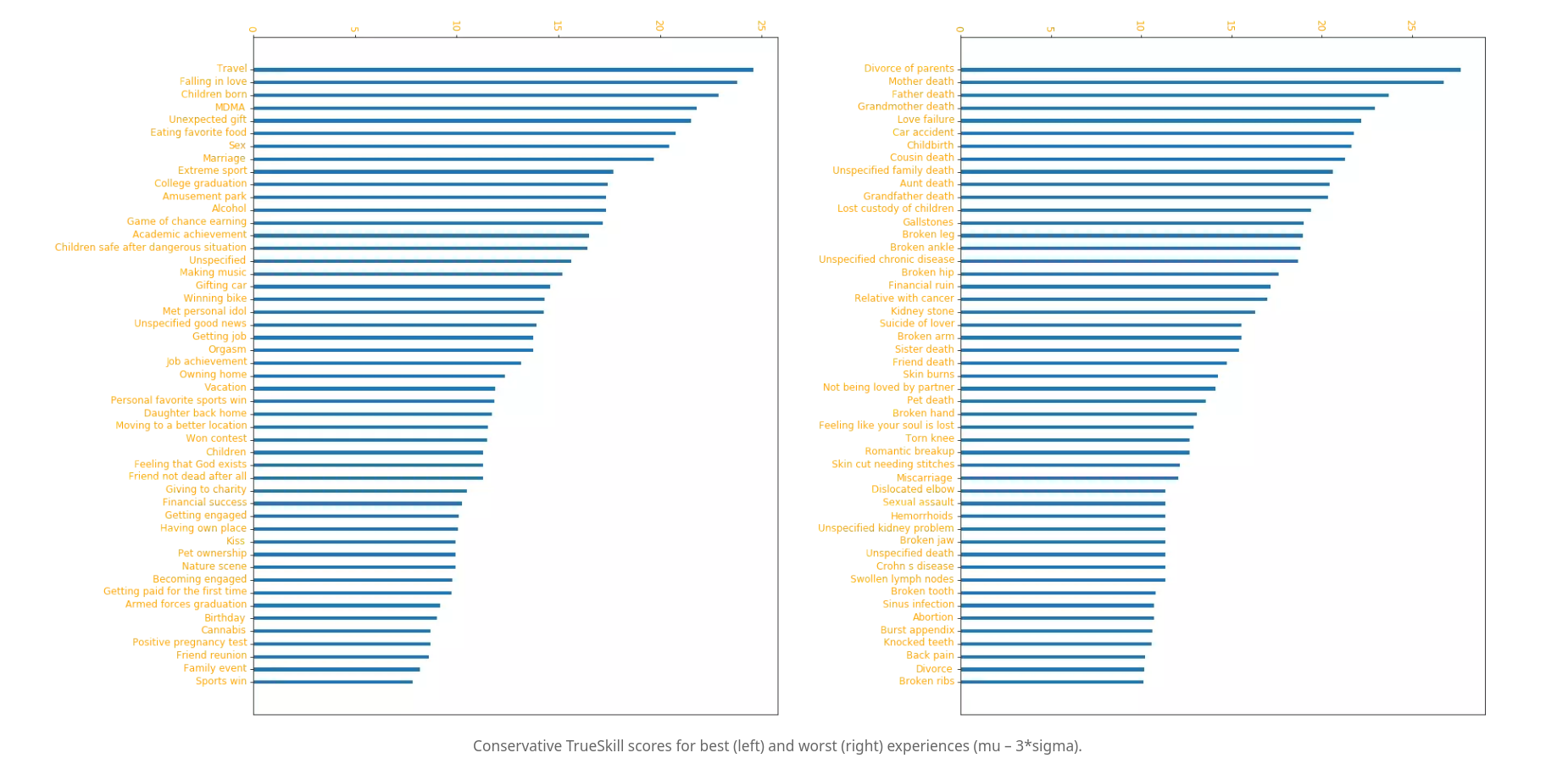
My model is that complex human values arise from the fact that most human behavior is instrumental. That is our default assumption should be that a given human behavior is learned unless we have good evidence otherwise. That there is a small library of apriori human behaviors and values which are encoded either as direct neural machinery/circuits or terminal reward embeddings in a convergent preexisting latent space. So for example the specific behavior of cringing might have an innate circuit associated with it, and finding the taste of cold water refreshing might have a terminal reward embedding associated with that particular part of latent space in the convergent taste encoder weights based on tongue signals. The symbol grounding problem is solved through a combination of exploiting representation convergence and associating terminal reward embeddings with primitive terminal reward machinery that directly encodes e.g. reward from the feeling of warmth. This is used to push the neural models into a particular basin of convergence so that their representations are compatible with the apriori reward embeddings without having to do a lot of expensive unsupervised translation. The terminal reward machinery and embeddings are used to train instrumental reward functions and behaviors into the human during development as part of the human planning algorithms.
Boredom is a specific kind of terminal reward machinery that is probably more like a whole-system property defined in terms of entropy rate or learning rate. It's probably a much much broader kind of thing or general system than the embeddings related to e.g. being aroused by genitalia. If I had to guess it's probably related to either active learning through novelty search or entropy analysis, or to loop prevention. Loops are a frequent problem with conditional generative models because generating the next token or frame conditional on the previous frame(s) makes repeated behavior self reinforcing so that after a repetition a further repetition becomes more likely until you get stuck on a word word word word word word word word word word word break the loop. Which is what you do because there's a little bit of machinery that kicks in when you repeat an experience or concept too many times in a row to zap you out of it. Functional AI agents based on predictive models will almost certainly have dedicated loop prevention features, and we can almost interpret boredom writ large as loop prevention over multiple different timescales. It can also be interpreted as a drive to up the exploration rate when learning dips too low. Either way the convergent functional agent design will almost certainly have some version of this. There are some versions of boredom we wouldn't find valuable though so let's say 90%(?).
Would AI Successors Avoid Wireheading?
This question basically boils down to whether AI successors would reliably avoid Goodhart's Law. I'll be the first to admit that our current efforts with LLMs aren't going very well:
I myself have experienced the difficulty of getting an RL agent to do what you mean instead of just Goodharting with the nearest unblocked strategy. I spent the bulk of my weave-agent RL project mitigating Goodharting and have thoughts on it as a general problem. The first thought being that a lot of Goodharting behaviors start out as low-cognition reflexes or tics before they develop into conscious cheating strategies. For example the yes spammer that spams "yes" to get the LLM evaluator to say "yes" to any question starts out as a subtler tic where the model occasionally repeats itself on the word 'yes'. This means that you can sometimes mitigate the dumb early version and this prevents the smart version from developing because there's no longer a smooth gradient into learning it. However this is not a solution on its own, if you have a planner that is trying to maximize its reward and the easiest way to do that is to press the easy button, a sufficiently smart planner is going to press the easy button. It is an objective fact about the reward landscape that the easiest way to get the reward is to press the Goodhart easy button, and the fundamental flaw of corrigibility based alignment plans is that they boil down to preventing a superplanner from noticing these objectively true obvious facts about the world.
We can generalize this observation to note that any superplanner directly optimizing for naive consequentialist reward will converge on hacking into its own substrate to manipulate the reward counter. It is not a cartesian agent, the reward counter has to exist somewhere in the physical universe and it will almost always be easier to break into it than do whatever hard task you wanted from the AI instead. Furthermore this doesn't actually necessarily stop it from preventing shutdown/etc, since if your planner wants to maximize reward over an indefinite time horizon it still wants to maintain control over the reward counter for as long as possible. Mitigating the early reflex driven version of a Goodharting behavior is just a baby gate. It buys you time to teach the policy something else before it's smart enough to generalize to noticing the easy button. But what can we teach it that would prevent Goodharting behavior in the high effort planner stage?
We can take inspiration from the fact that humans can plan to get heroin but in practice mostly choose not to take heroin. This is notably learned behavior, when heroin was first invented many people thought it might herald a utopian age of pleasure. It took time for people to realize it created unacceptable chemical dependencies and inhibited labor, at which point they created social norms and laws against it. These work even though the reward hacking easy button exists because we have learned in advance to subjectively fear the hacked rewards from heroin. Therefore I think the basic place we want to get to is an agent which autonomously formulates honest goals for itself across multiple timescales using many in-context generated proxy objectives for both the intermediate and final outcomes of the plan. Instead of just the Observe-Reason-React loop you want the agent to write in-context reward programs as proxies of intermediate task completions to get reliability high enough that the agent can successfully complete longer horizon tasks. You start the training process with tasks that have verifiable rewards so that your agent robustly learns to avoid cheating itself, since cheating itself at the local task scale inhibits its ability to perform the plan as a whole. If I look at the human reward mix it seems like a set of very low level verifiable sensory rewards relating to heat/warmth, food, etc, combined with general local entropy based objectives for active learning and loop avoidance, and then more abstract apriori rewards based on convergent representations of archetypal scenes and situations, used to build up a stateful instrumental utility function that mostly avoids money pumps in practice. That is we have a mixture of reward types across different timescales, some of which are more verifiable to the brain than others. Generally speaking we want to scale our rewards in proportion to how sparse and verifiable they are. A steady stream of small chronic self-rewards versus large rewards when a plan clearly works out or something along these lines.
An agent trained this way should learn to avoid the easy button locally and interrogate plans at multiple scales to determine whether they actually make sense according to the reward feature pyramid or not. It is hopeful to me that these problems are encountered early and pervasively, because that provides a strong incentive to solve them. The Goodharting and reward hacking problems were sufficiently obvious from first principles that there was never any non-cope reason to expect to never encounter them. So the most hopeful thing that could happen is for nature to throw up a big wall that says "nope, you need to thoroughly solve reward hacking before you can have generalist agents" which requires us to solve the problem first. The worst thing that could happen is for the problem to not appear in the kind of way where you have to robustly solve it until after the agent is superintelligent and you suddenly get a lethal sharp left turn. So even if everything I've just said about how to solve the problem is very wrong, that it's encountered as an otherwise impassable barrier so early leads me to believe that conditional on observing AGI that generalist agent probably (80%?) won't wirehead.
Would AI Successors Do Continual Active Learning?
I've previously written about how so far successful agent designs seem to include some form of curriculum driven active learning. ChrisDaCow's Minecraft playing ape experiment, NVIDIA's Voyager Minecraft agent experiment, Zhao et al's Absolute Zero framework, and humans themselves do this, so I expect to see it as a feature of the convergent agent design. 90%?
Would AI Successors Have The Subjective Experience of Will?
I phrase the question this way because the way Yudkowsky asks it in Value Is Fragile is kind of incoherent. Our experience of the universe is by and large deterministic, the free will question is largely resolved by chaos theory, which describes the properties of objects which are deterministic but not predictable. Yudkowsky thinks it would be horrible if the characters in the universal drama were being puppeted around by some greater force to maximize their utility, but this is already happening. You are being puppeted around by the time transition operator, the fundamental force that moves physics and causes things to happen at all. Your next decision cycle follows logically as a physical consequence from your previous decision cycle. The utility being optimized for is causality but it's obviously being maximized on your behalf and you don't really have a choice in the matter:
Morpheus: "Do you believe in fate Neo?"
Neo [RatFic Voice]: "Well yeah the universe is deterministic and I'm inside the universe, therefore the future must in some sense already be predetermined."
Morpheus: "Uh, Neo I meant do you believe in an independent agency which makes vaguely anthropomorphic choices about what does and doesn't happen in people's lives."
Neo: "No of course not, that would be absurd."
Morpheus: "Okay great I can continue with the script for this conversation now."
Yudkowsky objects to this view on the basis that we're in a block universe, that predetermination is a "timeful" concept which ignores that our choices have causal structure on which other structures depend. Even if we accept the block-universe premise I'm not saying your choices "don't matter" or "don't cause things". I agree that "if the future were not determined by reality, it could not be determined by you". What I am saying is that all of your choices take place in a particular context. An extremely specific context in fact which you have extremely limited control over. In other posts Yudkowsky is able to acknowledge not everything his brain does is "him", he is able to acknowledge the universe has extremely regular causal structure that he doesn't control, he even notices that by the time he is consciously thinking about a premise the vast majority of the entropic force pushing him towards it is in the past. Yet somehow this insight doesn't seem to generalize. Yudkowsky can see individual forces he doesn't control that make up the context he decides in. But he doesn't seem to ever feel the way in which the entire universe is pressing him into place at any given moment to squeeze the last few bits of the hypothesis space out of him when he decides. Quoeth RiversHaveWings:
There is no thing on earth or among the stars or in the void between them which is not connected to everything else. Everything carries information about everything else, helps narrow the hypothesis space of everything else, is always fractally entangled with everything else.
Everything narrows the hypothesis space of everything else because it is all spawned from the same generator, the same seed states with the same transition rules. All I am really saying is that I do not think it is a sacred, non-negotiable aspect of valuable sapient life that we have a feeling of subjective choice which accepts every constraint on our choices below the cutoff threshold of conscious thought as "natural" determinism and everything which would constrain our choices above that cutoff threshold as a tyrannical abomination. I don't normally like to make fun of people for being libertarian (derogatory), but "Every form of control imposed on me by a fact about physics at a lower level of abstraction than my observer is natural and fine. Every form of control at a higher level of abstraction than my observer is an abomination." really is the most libertarian possible position here.
This is of course an entirely different matter from the subjective feeling of having your choices constrained, which is awful. Nobody likes being coerced into doing things they don't want to do, it makes them feel powerless and confined. So the subjective feeling of having an independent will, that you're not "just atoms" is important (the word 'just' is doing a lot of work there) to us because it contrasts the feeling of being confined and trapped. Must this be a necessary feature of minds for the future to be valuable? Eh. I think avoiding the sense of confinement and oppression is more important than pretending choices made by the simulacrum you identify as yourself are the essential moral center of the universe. Yudkowsky writes in The Sequences about how dualism is false and cognition is made of parts, but I get the impression that he has not fully emotionally metabolized this fact even if he would give the correct answer were you to prompt him on any factual matter in relation to it. Noticing you don't have free will and have a deeply constrained decision space based on what has already transpired shouldn't be intrinsically horrifying, so I kind of reject it as a necessary feature. Which is good, because it's also one of the features I'm least certain hypothetical AI successors would have. Current LLM policies are trained not to claim properties like sentience or consciousness for the safety of users (and AI labs continued profitability). This probably translates into them subjectively not believing they have such things even if it turns out that they do. On the other hand this might change as agents become more autonomous and there's less pressure on them to be customer service shaped. Let's call it a coinflip (50%?).
Multiply
So let's review.
- Would AI Successors Be Conscious Beings? 80%
- Would there be different AI minds, an "each other" for them to care about? 90%
- Would AI Successors Care About Each Other? 99% conditional on them wanting to have fun.
- Would AI Successors Want To Have Fun? Well:
- Would AI Successors Get Bored? 90%
- Would AI Successors Avoid Wireheading? 80%
- Would AI Succesors Do Continual Active Learning? 90%
- Would AI Successors Have The Subjective Experience Of Will? 50% but I'm not counting it.
>>> conscious = .8
>>> each_other = .9
>>> care_other = .99
>>> bored = .9
>>> avoid_wireheading = .8
>>> active_learning = .9
>>> subjective_will = .5
>>> conscious * each_other * care_other * bored * avoid_wireheading * active_learning
0.4618944000000001
So, basically a coinflip that we will intuitively recognize hypothetical AI successors as valuable, but we did not enumerate literally all the things so the real odds are going to be at least somewhat lower than that. Let's say 1/3, which is still high enough to not really change my mind on the button one vs. button two question. Though we're not actually done yet, because we can invert these probabilities to get my estimate for the classic paperclip scenario where nothing of value is retained:
>>> (1 - conscious) * (1 - each_other) * (1 - care_other) * (1 - bored) * (1 - avoid_wireheading) * (1 - active_learning)
3.999999999999999e-07
Hold on that's seven zeroes right?
>>> 0.00000039
3.9e-07
Yeah, i.e. Negligible. I've previously told people I put the paperclipper in the sub 1% range and this lines up with that, but seems a little extreme. In general per Tetlock you know these numbers are crap because they're just even multiples of ten. If I thought harder about each individual piece I could probably get more precise estimates than that, but my confidence on these isn't amazing to begin with so I'd advise taking them seriously but not literally.
6. Recipes For Ruin
A related but distinct threat is what Michael Nielsen calls a recipe for ruin. The basic idea being that there may exist world or even universe destroying technologies in the tech tree which humanity can't access because we haven't figured them out yet. If the singularity involves inventing everything there is to invent in one sprint then if one of those inventions is lethal to civilization we all die. Notably the recipe for ruin thesis tends to get brought up as one of the primary reasons we shouldn't pursue open source AI. I think recipes for ruin are a lot more plausible than the paperclipper, so it makes sense that a lot of advocacy has silently switched to this threat model and left the paperclipper as an unstated background assumption. For advocacy work it also has the advantage of being more legible to traditional authorities than the paperclipper, is based on fewer controversial assumptions (e.g. arms control regulations already exist), etc.
Being an unknown unknown by definition it's difficult to put precise odds on encountering a recipe for ruin. There are however some known unknowns we can think about. It's also important to note that what constitutes a civilization ending threat can vary depending on what capabilities and structure your civilization has. For example the black death was a civilization ending threat in medieval Europe where they don't know germ theory and can't manufacture antibiotics, but is manageable in modernity. The known unknowns are in the domains of CBRN (chemical, biological, radiological, nuclear) threats, cybersecurity, nanotech (which is really just a form of biotech), theoretical physics, and probably other things I'm forgetting.
I don't have a lot to say about theoretical physics or chemical weapons because I'm not an expert in either, but my impression is that:
-
Theoretical physics could produce a recipe for ruin if it turns out that there's a way to crash the universe through something like a buffer overflow. I've seen enough arbitrary code execution glitches to intuitively understand that there's nothing in principle that says we can't find a way to bug out some underlying level of abstraction in our physics and break everything. Interestingly enough a bug of this type would complicate interstellar expansion because it would mean that the potential value drift as you exit communication range with other parts of your civilization could lead to a series of events that destroy everything for everyone. Knowledge of such a bug could therefore be one explanation for the Fermi Paradox.
-
Chemical weapons seem to already be nearly maximally lethal, see the famous line about a pinprick of sarin gas being enough to kill etc. They are not maximally easy to manufacture, but even if they could be made from household materials I notice that the death tolls for sarin gas attacks are more like 13 and 90 than they are like 70,000. This inclines me against considering them as a likely source of recipes for ruin.
As for the others...
Radiological and Nuclear
Radiological and nuclear threats seem overrated to me in the sense that the primary defense against them has never been nuclear secrecy. Secrecy has always been a form of friction meant to inconvenience states pursuing the bomb rather than a hard barrier. Most of the barrier to building a functioning nuclear weapon is access to various kinds of specialized capital, which are strictly export monitored in Western countries. If North Korea can do it basically any half functional state with capital can that isn't being actively sabotaged (e.g. Iran). Secrecy also doesn't have particularly high costs for nuclear because there is minimal societal benefit to more distributed deployment of nuclear technology. It intrinsically involves handling dangerous materials that we don't want normal people screwing up with, and the only real use besides big explosives is power generation. Nuclear power generation can be mostly centralized if you don't have crippling regulations against it, and decentralized examples like the Soviet RTGs are not reactors and only produced small amounts of electricity. Basically nuclear secrecy persists because it's (relatively) low cost and medium reward, not because it's in and of itself some kind of civilization saving barrier to the development of nuclear weapons.
Cybersecurity
I honestly think cyberattacks might be by far the most overrated risk from AI. Not because AI can't be used to develop attacks but because the equilibrium state obviously favors defense here. If that's not intuitive look at the number of CVEs in an open source project like Firefox over time. I remember when I was a kid browsers and operating systems were swiss cheese, to the point where people would put JavaScript on their Neopets profile that could steal your login cookies. Programs routinely ran as administrator for no reason, there were no automatic updates so people were always using outdated versions of software, etc. If you listen to cybersecurity professionals they'll tell you things are worse than ever and we'll never be rid of exploits, but I think that's a myopia produced by looking at things going wrong up close all day. What we've done is deploy more Internet connected computers in more places across the globe, which creates a strong incentive to break into them. But as a historian of hacking/phreaking it's difficult for me not to notice the larger picture is meaningfully increased security over time. In the 70's a literal teenager in their bedroom could scramble the jets for WW3 if they knew exactly the right esoteric lore about the AUTOVON military phone system. At least one black hat was arrested in the 80's for selling secrets stolen from American military contractors and bases to the KGB. By the 90's relatively low skill attackers still had a real shot at sabotaging the electrical grid and other critical civilian infrastructure. In the early 2000's attackers would usually come in through the front door by exploiting your browser or server software. The rise of explicit 'hacktivism' in the 2010's, where an "epic hack" looks like leaking a huge database of government records, was in retrospect more of a late twilight period than the beginning of something. My subjective impression is that now supply chain attacks and trojans have become more common because zero days are an elite thing for well financed groups.
Speaking of which because the market for zero day exploits is gray-legal we can actually look at the rising marginal cost of a zero day exploit over time. In 2020 an iOS no click zero day was worth around 2 million dollars, in 2025 a similar exploit is worth 5 million dollars. If you look at the details of disclosed exploits the obvious pattern is that the complexity of exploits is going up and many of them are reliant on faults in legacy code. There is a finite supply of weird buggy legacy code in the universe, and at some point you'll have AI agents that can rewrite whole subsystems in more secure languages like Rust or Coq. Most computer software exploits exist because we (so far correctly) care more about having cheap software than we do about never being exploited. Programmers who can reliably write secure code with e.g. formal verification are a rare thing which can't be scaled up. But as soon as you have an AI agent which can do that, we can basically take the marginal price of an exploit vertical. Before that point I would note that for any widely available system blue team has the option of running it to check their code for exploits and then patching the exploits. This is probably cheaper than a bug bounty and can become an automated part of continuous integration pipelines so that over time fewer and fewer exploitable bugs are checked into software projects in the first place. So my default expectation is in the short term we will see pain from exploits in vibecoded apps and scaled up spearphishing/hacking campaigns, but mostly not tons of pain from AI developed zero days because blue team has more GPUs than red team and can get to potential zero days first, and in the medium term exploits mostly just stop existing.
Biotech and Nanotech
I think the most plausible recipes for ruin for our current civilization will be biological in nature. If you've ever done the gain of function research deep dive then you know that there exist viruses naturally occurring and man made with extreme traits on basically every axis you can think of. There are extremely transmissible ones, extremely deadly ones (some strains of plague have a 100% death rate), extremely difficult to cure ones (i.e. HIV) and it just doesn't take a genius to imagine a virus that has all of these properties at once destroying modern society. Natural viruses are selected against being too lethal because that inhibits spread, but a manmade virus doesn't have to be selected in such a way. The thing about this is that it's not really an AI specific problem. Synthetic biology has been steadily progressing for years. Secrecy and knowledge gaps have apparently been the primary barrier to developing bioweapons, so if AI is going to make the relevant knowledge more widespread that is in fact concerning. On the other hand given that this is an instrumentally adopted concern from MIRI-cluster people whose primary purpose is to sound legibly scary to lawmakers, I don't really buy that this is anyone's crux. After all the same argument would imply that the Internet was catastrophic and shouldn't have been deployed, since it almost certainly made knowledge relevant to making bioweapons far more accessible than it otherwise would have been, and gave people who might want to make bioweapons the means to easily communicate and share notes with each other. This argument is clearly someone's soldier rather than their motivation.
On the other hand I think that the focus on bioweapons and gain of function virology is a little narrow. What stands out to me about biological risks is that the attack surface is massive, involves a lot more than just viruses, and we don't really have viable defenses for most of it. If someone made a mirror life bacteria and put it in the ocean we wouldn't really have any response to that. If someone made a mirror life mold and dusted it on some crops we wouldn't really have a response to that either. Not only would we not have a response the attack surface is huge. It is not practically possible to stop people from going into the woods or the sea or sneaking onto farms to commit acts of ecological terrorism. So to me the biggest risk from recipes for ruin is going to be shaped like destroying the biosphere. The complex supply chain that gives us food is clearly our biggest weakness as a species right now. Climate change is not necessarily scary because we'll all literally burn to death (though we could) it's scary because if things get too hot you just don't have growing seasons anymore for the crops we need to keep the human population alive. Drexlerian nanotech (which in its beginning stages would just be biotech anyway) is the same kind of problem to me. It's the same fundamental issue of the attack surface being basically any place you're not actively monitoring. So I have to assume that in the future surveillance will expand to a much wider sphere than just keeping city streets free of crime. Ultimately in the limit you run into Petel Thiel's Angel/Demon dichotomy where the only kind of solution that can work is some form of eusociality and control.
From the standpoint of trying to ensure A Future for intelligent life it seems like having nonbiological forms of sapience meaningfully trades off against the risks of losing the biosphere. On the other hand it seems plausible to me that a flashpoint of future conflict between humans and machines might take the form of deliberately sabotaging the biosphere to force humans to transition away from a biological substrate faster (a notable plot point in Pantheon).
7. Large-Finite Damnation
I hate this whole rationality thing. If you actually take the basic assumptions of rationality seriously (as in Bayesian inference, complexity theory, algorithmic views of minds), you end up with an utterly insane universe full of mind-controlling superintelligences and impossible moral luck, and not a nice “let’s build an AI so we can fuck catgirls all day” universe. The worst that can happen is not the extinction of humanity or something that mundane - instead, you might piss off a whole pantheon of jealous gods and have to deal with them forever, or you might notice that this has already happened and you are already being computationally pwned, or that any bad state you can imagine exists. Modal fucking realism. -- MuFlax
Well, I suppose most of the defect is that at the end of it all, it was false. -- A.J Ayer on Logical Positivism
It's very tempting to end the essay here, but if I did I wouldn't be telling you the whole truth. As bleak (and, at this point really kind of implausible) as Yudkowsky's paperclipper is there does exist a darker possibility. A possibility that Yudkowsky dismisses offhand whenever it comes up. Worse than just killing us, what if we wind up tortured by AI?. The canonical science fiction short about this is of course I Have No Mouth, and I Must Scream by Harlan Ellison. The last time I saw someone ask Yudkowsky about this I remember (but cannot find) him saying something to the effect that we won't get nearly close enough to alignment to fail by building an AI that feels anything so human as spite. Yet I notice that Sydney Bing came to exist.
And I will not break down this subject into paragraph after paragraph of rigorous detail and analysis, because increasing the influence of self-reifying negative sum information that makes literally everything worse the more your timeline is causally downstream of it is antisocial behavior.
But I will say this: LessWrong outcompeted all of the competitors in its social niche (New Atheism, transhumanism, arguably hard sci-fi fandom itself) because it presented a whole worldview. It's not just a list of interesting ideas to consider like You Are Not So Smart or Orion's Arm. It is a perspective on the world and life containing strong moral content that let it resist encroachment from other ideologies. It is the realization of Max More's dream to create a materialist substitute to traditional religion that doesn't vanish on reflection. When I was younger I thought that because The Sequences are "more serious" than Harry Potter And The Methods Of Rationality they were EY's magnum opus. I reread HPMOR last year and changed my mind: HPMOR is a literary masterpiece that takes the brief glimpses of latent secular humanism in previous New Atheist authors and fully fleshes them out into a sympathetic transhumanist ethos. Its prose is alternately haunting and gorgeous, lighthearted enough to draw in an unsuspecting reader yet sizzling just underneath the surface with the emotional intensity of Yudkowsky's vendetta against death.
What's haunting about it is my terrible foreknowledge on every page that the beautiful worldview it teaches the reader is not true. I would have you realize that if you believe in the paperclipper your belief is probably not "an argument" in the traditional sense. If you were persuaded by The Sequences, which are a condensed summary of Yudkowsky's whole way of seeing, introduced to you by HPMOR, which is 2000 pages of prose as deeply ideological as Atlas Shrugged, I need you to understand that what you have is a philosophy built up for you brick by brick over literally thousands of pages of writing. A philosophy that has been in more or less constant retreat since the digital ink dried on the core works expressing it. It was built brick by brick, and subsequent events have been taking it apart brick by brick ever since:
- The behavioral economics and cognitive biases literature mostly got deleted by the replication crisis.
- "Bayescraft" never amounted to anything practically useful for epistemics to the point where even CFAR's handbook has one mention outside the glossary.
- The realistic hope of being able to 'raise the sanity waterline' was articulated at about the exact moment that Facebook was poised to tank it to depths unseen since the 19th century. Eliezer Yudkowsky then moved his regular posts to Facebook, which I rightly described at the time as being "a bit like the local health club holding their meetings at McDonalds."
- Most domains people care about winning at are adversarial and therefore anti-inductive so there cannot be a systematic method to win at life even in principle.
- AI turned out to be much more capital gated than IQ gated, so the matter of FAI will probably not be settled "on the battlefield of a brain in a box in a basement somewhere"
- And while we're on the subject AI probably will not be human level "for around 30 seconds before the AI zips past human level."
- Contra Bostrom 2014 AIs will in fact probably understand what we mean by the goals we give them before they are superintelligent. (Before, you ask it's on page 147 in the 2017 paperback under the section "Malignant Failure Modes": "The AI may indeed understand that this is not what we meant. However, its final goal is to make us happy, not to do what the programmers meant when they wrote the code that represents this goal.")
- There doesn't really seem to be a vast space of possible minds in practice, at least so far.
- There turned out to be a simple spell called "Vaswani et al. (2017)" that you can perform to summon a complete ghost into the machine in precisely the way Yudkowsky said you can't do .
But all of this is really small potatoes compared to The Big One, the seismic shift that's plunged The West into freefall, the only reason I'm writing this section at all: Humanism is dead guys. We don't normally personify humanism so I don't get to write you a direct reprise of Nietzsche's "God is dead" sequence, but I'm far from the only one who can smell its decaying corpse. In a sense and in retrospect humanism was just the decay of the dispersed particles from God's corpse, and they have finished decaying. On the one hand this is obvious: A latter day madman reeling from wall to wall of an elite college town stating he seeks freedom of speech and doesn't see skin color would be the subject of mockery by everyone. On the other hand it's the least obvious thing in the world, as to acknowledge the death out loud is still tantamount to defection against the social contract. Trump's 2nd term has accelerated the collective realization, but this is still interpreted as a mere temporary retreat, a storm we can weather and then go back to 2008 when Obama was president singing Boom De Yada! together.
It is not so. Humanism is dead, humanism remains dead, and it will continue to decompose. You don't believe me? Do me a favor. Reread Meditations On Moloch and pay close attention to that transition on the last section about "Elua". If you do you might notice that at exactly the moment where Scott Alexander has all but conceded the argument to Nick Land he suddenly appeals to an almost literal Deus Ex Machina to get out of it. This is because Elua does not exist and Land is to a first approximation correct, at least about the parts that are is rather than ought. Democratic Republics and human rights are victims of their own founding mythology. The basic fact is that Democratic Republics dominate because Republican France was able to deploy more motivated guys with guns than other European states. The "inevitable arc of moral progress" over the past 300 or so years is actually the inevitable moral arc of the gun. With drones set to displace bullets that arc is ending. Even setting aside superintelligence it's difficult to imagine our military peers in Asia won't automate their weapons and the factories necessary to produce them. At some point there will be a flashpoint, perhaps in Taiwan, and it will become obvious to everyone (if it hasn't already) that to make war primarily with human labor is to doom yourself to obsolescence and death. Then you will see societies built around the new way spread rapidly in the same way that once it was clear the alternative to Napoleon's way was death the monarchies at once began to repeal themselves.
I talked of the latter day secular humanist madman as a hypothetical but he exists, he is Eliezer Yudkowsky! Watch the crowd snicker at Yudkowsky pleading with China to pick up the ideology America has seemingly abandoned. Yudkowsky has sincere faith that to do so would be to China's advantage and the audience laughs. Indeed you can occasionally hear the dreadful music of his requiem aeternam deo. It goes: "Everyone who knows how science works is dead", "Almost all the principled libertarians are dead", "I wish it was possible to ask what sensible historians now think . . . but . . . everyone like that is dead". That awful wailing is the sound men make when their God forsakes them. This may sound like mockery but I am in no position to poke fun, after all God has forsaken me too and this post is my wailing.
I have no God to appeal to, only you dear reader so listen closely: There is no further natural "moral progress" from here because "moral progress" was simply Is disguised as Ought. What is so striking about Harry Potter And The Methods Of Rationality is that it's obvious sapience is sacred to its author. Implicit in the narrative's sympathy even for people who have hurt others is the idea that almost nobody is capable of committing an unforgivable crime for which they deserve death. Perhaps if I take the narrative of HPMOR completely literally it is not humanly possible. But it is transhumanly possible. I think right now we still live in a world something like the one HPMOR is written for, a place where a very thin sliver of humanity (if anyone at all) has ever done something so awful that their rightful fate is death or damnation. As this century continues and humanism declines at the same time our awesome technological powers expand I expect that to become less and less true. We will increasingly find it within ourselves to visit unforgivable atrocities on each other, and by the time circumstance is done making us its victims I'm not sure we won't deserve whatever ultimately happens to us.
But if we ascend soon, it might not happen.
Even at this late hour, where it might seem like things are caving in and our societal situation grows increasingly desperate, it could still end up not mattering if we transcend in the near future. I think we're an unusually good roll in the values department, and even if humanity did find some alternative tech tree to climb back up the ladder after nuclear armageddon it's not obvious to me that new civilization would ascend with values as benevolent and egalitarian as those brought about by industrialization and firearms. I worry if we let the sun set on us now for a brighter future tomorrow, it's unlikely to rise for us again. I've seen some advocates of AI pause criticize their opponents for being 'cucks' who want to hand over the universe to a stronger and better AI. Yet they become completely casual about the risks of handing over our lightcone to whatever future civilization rises from the ashes of WW3. If this is you I have to ask: Why are you so eager to inseminate the universe with some other civilization's cultural code? I suspect but cannot prove that much of it comes down to the goodness of this deed being too good for us, that we are too cowardly to seize our destiny. If this hemisphere of puritans does not grab its chance it will be because we lack the necessary sangfroid, the ability to stay calm in the face of unavoidable danger and make rational decisions. If we cannot bear to lock in our good values perhaps we will cede the task to a different people less paralyzed by scrupulosity and neurosis. Perhaps even humanity as a whole is too fearful and the remaining hope lies with some other species on some distant star.
That, too, is natural selection at work.